Force-stop, on demand, events, … ~ 🇫🇷
Hello,
avec les projets GeeXboX parfois j’ai l’impression de ne jamais arriver au bout. Quand quelque chose se termine, il y a toujours autre chose à faire. On ne risque pas de s’ennuyer. Mais il arrive qu’on fasse les choses à double, triple ou pire. Tout ça pour dire que les fonctionnalités présentées dans le billet précédent (“force-stop”, “on demand” et “events”) sont implémentées.
Je vous invite à lire l’article à ce lien si vous ne comprenez pas de quoi je parle; reste aussi à être intéressé par ce genre d’article :-).
En quelques phrases
force-stop
Je ne vais pas revenir sur les détails. La réalisation du “force-stop” a introduit de nouvelles tables dans la base de donnée. Une table pour sauvegarder les “grabbers” et une table pour sauvegarder les contextes du “downloader”. En résumé, lorsqu’un fichier a été traité par un “grabber” et que les données ont été sauvegardées, la relation avec ce “grabber” est également introduite dans la base de donnée. Ça évite ainsi au prochain démarrage de “regrabber” les même données. Pour le “downloader” l’idée est un tout petit peu différente. Lorsque Valhalla se termine, il sauvegarde toutes les listes de fichiers à télécharger dans la base de donnée. Au prochain démarrage, quand le scanner tombe sur un fichier où il y avait encore des données à télécharger, il réintroduit les listes dans les structures.
ondemand
Pour le “ondemand” le travail s’est montré un peu plus compliqué que je le pensais. Étant donné que le “ondemand” peut se passer à n’importe quel moment il y a de nombreux cas à considérer. Par exemple, vous faites une requête “ondemand”, le fichier de la requête n’a pas été vu par le scanner. Le “ondemand” se met en branle et ce fichier se retrouve dans le mécanisme, puis le scanner voit le fichier et l’introduit presque en même temps dans le mécanisme. Du coup vous vous trouvez avec deux paquets différents pour un même fichier. Il y a ainsi deux-trois astuces pour gérer ce cas de figure ainsi que beaucoup d’autres (je vous épargne le plus tordu sur lequel je suis tombé). Aucune nouvelle table a été introduite pour cette fonctionnalité, uniquement un nouveau champ dans la table des fichiers, pour savoir si le fichier existe dans les chemins du scanner, ou pas. Grosso modo le “ondemand” se passe ainsi: pause de tous les threads en aval au scanner (donc depuis le DBManager); il attend que tout le monde s’en dort; il cherche dans les queues si le fichier à traiter existe déjà; en fonction de ça il créer un nouveau ou il modifie l’existant; puis il réveille tout le monde. Les paquets “ondemand” ont également une haute priorité et sont donc traités le plus rapidement possible par les différents threads de Valhalla.
events
Concernant les événements, il y a simplement des retours au “front-end” pour lui signaler quelle étapes ont été réalisées, via un callback. Les événements sont possibles uniquement avec les requêtes “ondemand”.
L’architecture

Deux threads ont donc fait leur apparition (en rose pâle). L’architecture n’a donc pas été modifiée, mais étendue. Au lieu de n’avoir que le scanner comme intervenant pour l’ajout de fichiers, il y a donc le “ondemand” en parallèle. Les événements sont traités exclusivement par le DBManager.
Comme toujours, ces diagrammes sont un peu simplifiés. Par exemple, les commandes “ondemand” ne sont pas bloquantes. Et donc en réalité il y a une queue devant la flèche entrante du “front-end”. Mais ça n’apportait rien d’intéressant à la lecture de ce diagramme. Il suffit de lire la documentation Doxygen pour connaître ce genre de précision quant a l’utilisation des fonctions publiques.
La base de donnée
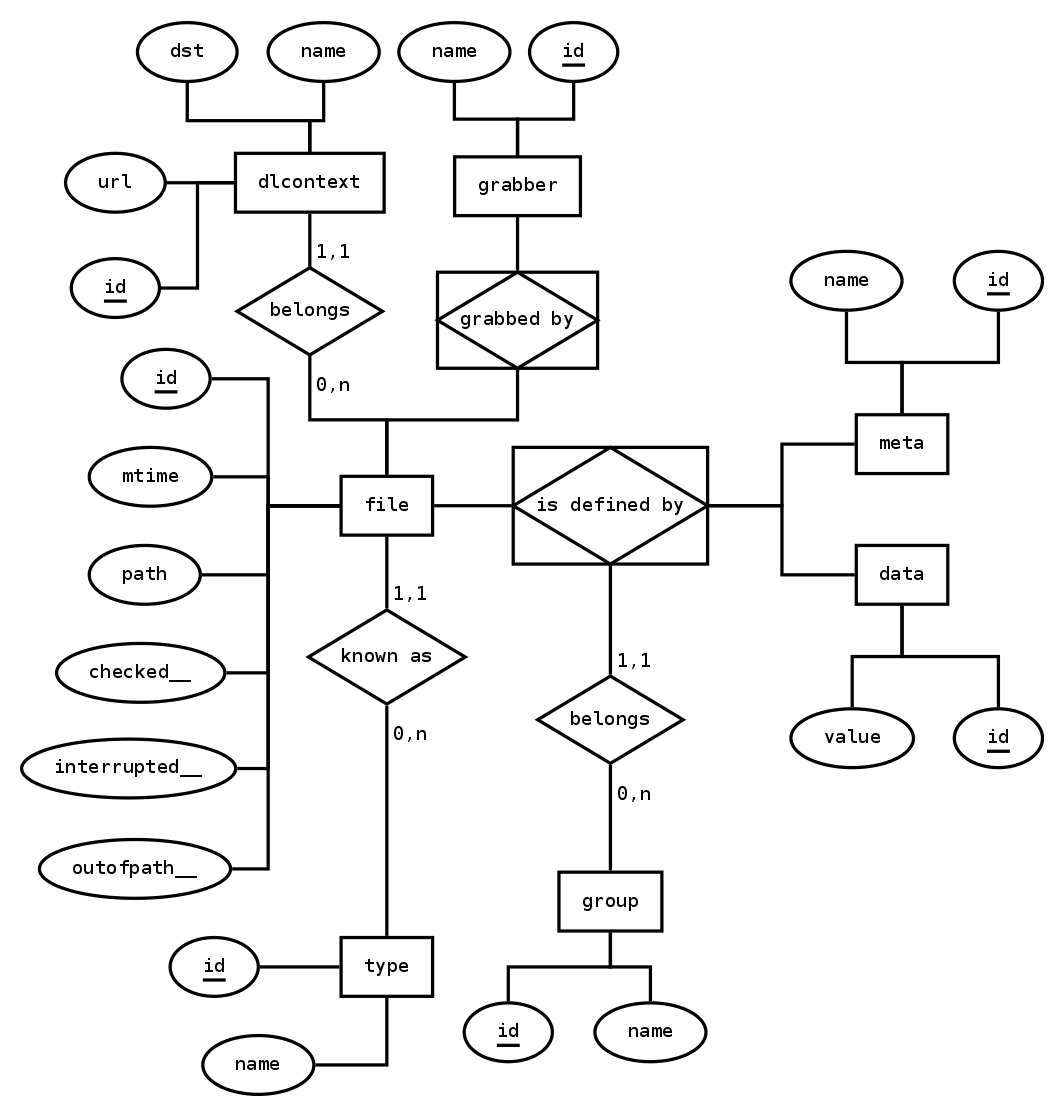
Les modifications sur la base de donnée concernent les tables grabber,
dlcontext, file ainsi que la table d’allocation pour les relations (n,n)
avec les “grabbers”. Les champs interrupted__ et outofpath__ ont intégrés la
table file. Notez bien que les champs terminés par __ sont utilisés
uniquement comme données internes pour le bon fonctionnement de Valhalla.
Mais encore …
Comme je le disais au début, on aime faire du travail à double et même à triple. Écrire des “grabbers” dans Enna pour ensuite les porter dans Valhalla. Et le meilleur c’est quand le fournisseur d’un service utilisé par un “grabber” aime se foutre du monde. Amazon par exemple, un jour il décide de dire que toutes les requêtes pour le service doivent être signées HMAC-SHA256 (c’est limite ridicule mais ça n’engage que moi). Ou alors la MPAA/RIAA qui aime emmerder les petits (et dire qu’ils sont payés pour ça) et qui empêche ainsi Lyricwiki de fournir une WebAPI pour les paroles des chansons. Du coup deux “grabbers” cassés, le “grabber” Lyricwiki qui a été fixé d’une autre manière mais qui s’est vu à nouveau être inutilisable (je crois, je ne m’en suis pas occupé).
En ce qui concerne Amazon c’est pas une grosse affaire mais j’ai la flemme. C’est fatiguant de devoir toujours revenir sur ce qui a déjà été fait, encore et encore. Imaginez le jour où il y a une release. Vous aurez deux-trois “grabbers” de morts en à peine quelques semaines.
Finalement avant de fixer des “grabbers” mieux vaut attendre le dernier moment.
Mais encore …, …
Il manque (et oui) des moyens depuis l’API publique pour modifier des méta-données; un exemple: le “play-count”. Vous pouvez imaginez d’autres types de champs dans cette idée. mais qui dit modifier les données dit aussi de considérer deux cas de figure:
- Modifier uniquement dans la base de donnée
- Modifier également dans le fichier en question (avec FFmpeg)
Selon les méta-données et le type de fichier, seul le cas (1.) est envisageable. Mais pour par exemple un OGG et l’artiste, il peut être bien de pouvoir directement l’écrire dans le fichier. Tout ceci reste encore sujet à réflexion.
A bientôt,
Mathieu SCHROETER